Module 23 Getting Data into R
This module explains how to enter data into R. Subsequent modules will explain how to use R to create the graphics and compute statistics and test results from these data.
23.1 Data in R
23.1.1 Create CSV File
For real data (i.e., several variables from many individuals) it is most efficient to enter data into a comma-separated values (CSV) file and then import that file into R. Creating a CSV file with Microsoft Excel is described below, though there are other ways to create CSV files (see FAQs on class webpage). This explanation assumes that you have a basic understanding of Excel (or other spreadsheet software).
The spreadsheet should be organized with variables in columns and individuals in rows, with the exception that the first row should contain variable names. The example spreadsheet below shows the length (cm), weight (kg), and capture location data for a small sample of Black Bears.
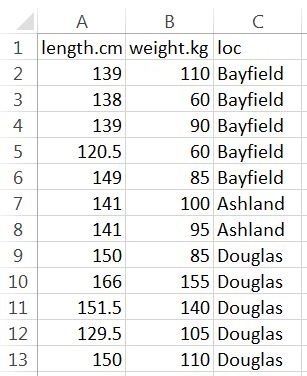
Variable names should NOT contain spaces. For example, don’t use “total length” or “length (cm).” If you feel the need to have longer variable names, then separate the parts with a period (e.g., “length.cm”) or an underscore (e.g., “length_cm”). Variable names must also NOT start with numbers or contain “special” characters such as “~,” “!” “&,” “@,” etc. Furthermore, numerical measurements should NOT include units (e.g., don’t use “7 cm”). Finally, for categorical data, make sure that all categories are consistent (e.g., do not have a column that contains both “bayfield” and “Bayfield”).
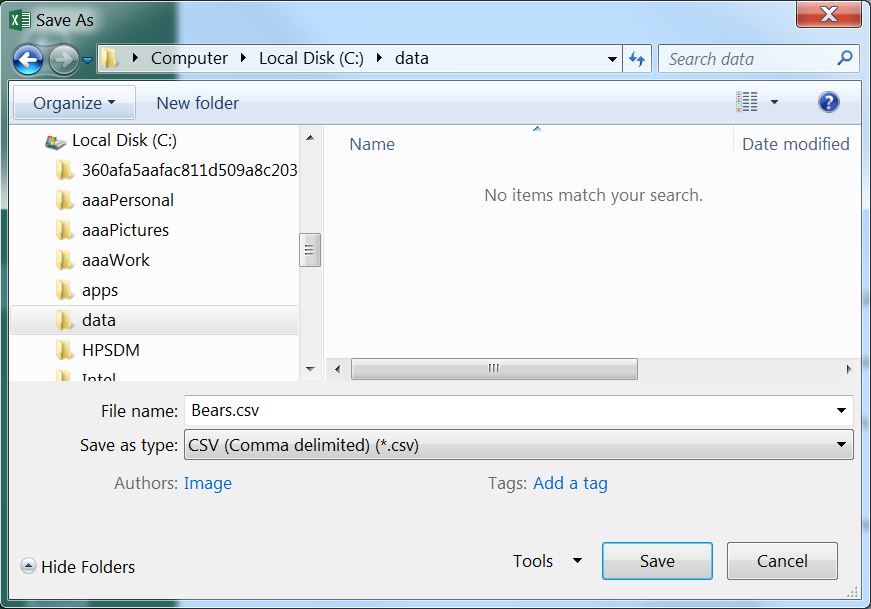
The spreadsheet is saved as a CSV file by selecting the File..Save As menu item, which will produce the dialog box below. In this dialog box, change “Save as type” to “CSV (Comma delimited),”77, provide a file name (do not put any periods in the name), select a location to save the file (this should be the same location as your assignment template file), and press “Save.” Two “warning” dialog boxes may then appear – select “OK” for the first and “YES” for the second. You can now close the spreadsheet file.78
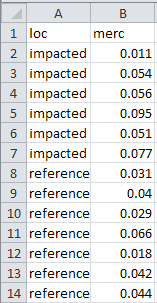
It is important that each row of the data frame correspond to one individual. This is critically important when data are recorded for two different groups (e.g., for a two-sample t-test; see Module 24). For example, the following data are methyl mercury levels recorded in mussels from two locations labeled as “impacted” and “reference.”
impacted 0.011 0.054 0.056 0.095 0.051 0.077
reference 0.031 0.040 0.029 0.066 0.018 0.042 0.044To follow the “one individual per row” rule, these data are entered in stacked format where the “reference” data are stacked underneath the “impacted” data and a column is used to indicate to which group the individuals belong. For example, the Excel file for data entry would look like the following.
Some of the data files that you will use are linked to on the pertinent assignment page (e.g., this link). In these cases, the data should be downloaded with the link (right-click, save as) and saved in the same directory or folder as your analysis notebook. The downloaded file is then read into R in the same manner as described above. Note that files provided by me will already be in stacked format and will already be a CSV file.
23.1.2 Read CSV File into RStudio
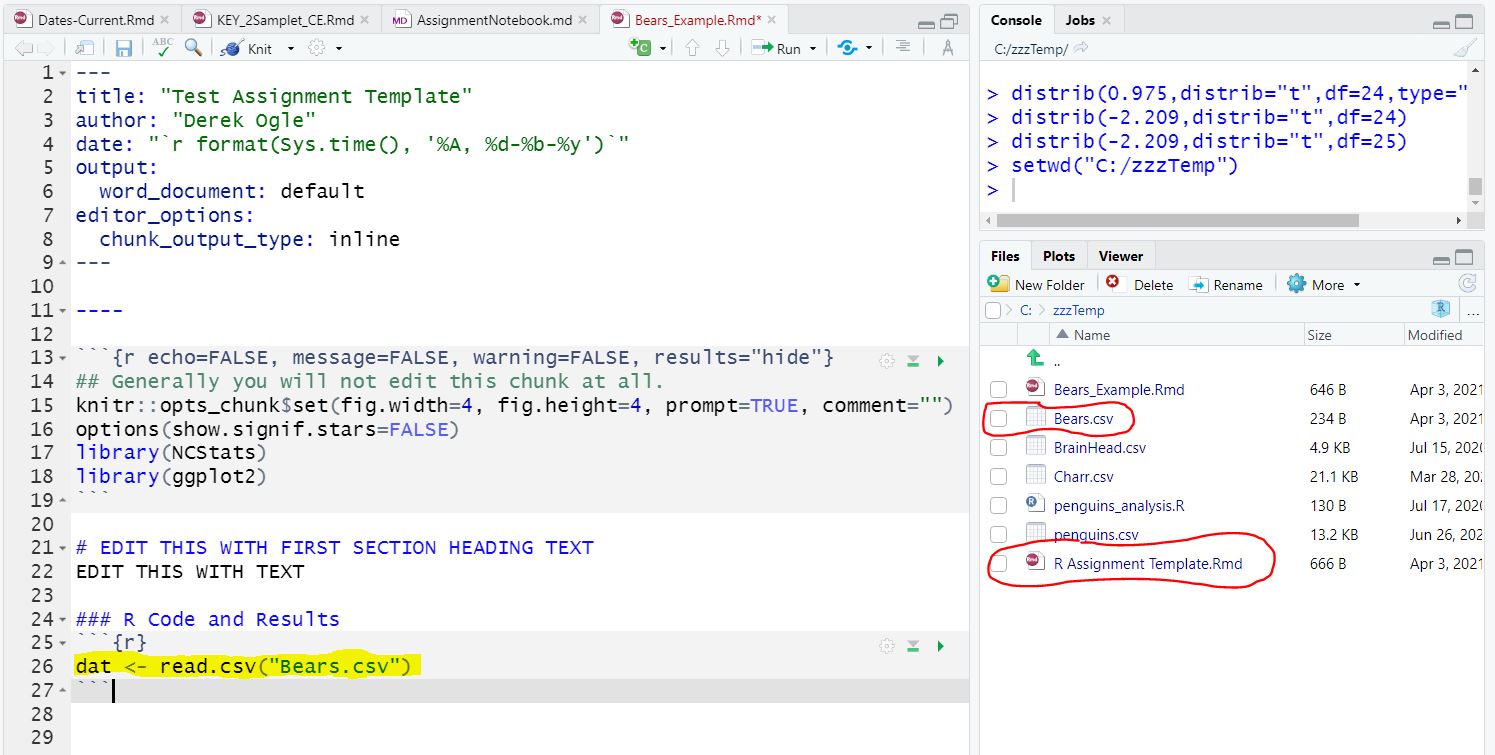
Use read.csv() in the first R code chunk of your assignment notebook to load the data from the CSV file into RStudio. The EXACT name of the data file is including within quotes within read.csv() and the results should be saved to an object. For example, the code highlighted in yellow in the graphic below was used to read the external “Bears.csv” file into an R object called dat. The circled items in the lower-right pane demonstrate that the “Bears.csv” file is in the same directory as the assignment notebooks file.
One should check the data in this object as described in the Viewing a Data Frame section below.
23.2 Viewing a Data Frame
R may be disorienting at first because you generally cannot “see” your data in the same way that you see it in a spreadsheet program. There are, however, several options for viewing your data. First, you can type the name of the data frame object to see its entire contents.
bears#R> length.cm weight.kg loc
#R> 1 139.0 110 Bayfield
#R> 2 138.0 60 Bayfield
#R> 3 139.0 90 Bayfield
#R> 4 120.5 60 Bayfield
#R> 5 149.0 85 Bayfield
#R> 6 141.0 100 Ashland
#R> 7 141.0 95 Ashland
#R> 8 150.0 85 Douglas
#R> 9 166.0 155 Douglas
#R> 10 151.5 140 Douglas
#R> 11 129.5 105 Douglas
#R> 12 150.0 110 DouglasTyping the name is adequate for small data.frames, but not useful for large data.frames. The entire data.frame is opened in a separate window by double-clicking on the name of the data.frame in the “Environment” tab of RStudio. Alternatively, you can view a subset of 20 rows of a data frame with peek(), the first six rows with head(), the last six rows with tail(), or the first and last three rows with headtail().
peek(bears)#R> length.cm weight.kg loc
#R> 1 139.0 110 Bayfield
#R> 2 138.0 60 Bayfield
#R> 3 139.0 90 Bayfield
#R> 4 120.5 60 Bayfield
#R> 5 149.0 85 Bayfield
#R> 6 141.0 100 Ashland
#R> 7 141.0 95 Ashland
#R> 8 150.0 85 Douglas
#R> 9 166.0 155 Douglas
#R> 10 151.5 140 Douglas
#R> 11 129.5 105 Douglas
#R> 12 150.0 110 Douglashead(bears)#R> length.cm weight.kg loc
#R> 1 139.0 110 Bayfield
#R> 2 138.0 60 Bayfield
#R> 3 139.0 90 Bayfield
#R> 4 120.5 60 Bayfield
#R> 5 149.0 85 Bayfield
#R> 6 141.0 100 Ashlandtail(bears)#R> length.cm weight.kg loc
#R> 7 141.0 95 Ashland
#R> 8 150.0 85 Douglas
#R> 9 166.0 155 Douglas
#R> 10 151.5 140 Douglas
#R> 11 129.5 105 Douglas
#R> 12 150.0 110 Douglasheadtail(bears)#R> length.cm weight.kg loc
#R> 1 139.0 110 Bayfield
#R> 2 138.0 60 Bayfield
#R> 3 139.0 90 Bayfield
#R> 10 151.5 140 Douglas
#R> 11 129.5 105 Douglas
#R> 12 150.0 110 Douglas
23.2.1 Structure and Data Types
Data in R will be designated as an integer (whole numbers), numeric (non-integer numeric values), character (strings), factor (group membership), or logical (TRUE/FALSE). Integer and numeric data types correspond to quantitative data. Character and factor data types correspond to categorical data, with the factor data type having special characteristics in R that we will exploit for certain analyses. These types of data will be discussed further as needed in other modules.
In addition to viewing the contents of a data object, it is useful to examine the structure of the data frame as returned from str().
str(bears)#R> 'data.frame': 12 obs. of 3 variables:
#R> $ length.cm: num 139 138 139 120 149 ...
#R> $ weight.kg: int 110 60 90 60 85 100 95 85 155 140 ...
#R> $ loc : chr "Bayfield" "Bayfield" "Bayfield" "Bayfield" ...In this example, it is seen that three variables were recorded on 12 individuals. The first variables – length.cm – is numeric, the second – weight.kg – is integer, and the last – loc – is a character variable. The unique values in a character variable may be seen with unique().
unique(bears$loc)#R> [1] "Bayfield" "Ashland" "Douglas"A character variable may be converted to a factor variable with factor(). In this course, the main reason for doing this would be to control the levels of an ordinal variable because R treats levels alphabetically by default. For example suppose that we wanted to order the levels of the loc variable from west to east (so, Douglas, Bayfield, and Ashland). For this purpose the variable is converted to a factor below with factor() and the order of the levels is controlled with levels=.
Make sure the levels are spelled EXACTLY as they appear in the data.
bears$loc <- factor(bears$loc,levels=c("Douglas","Bayfield","Ashland"))
levels(bears$loc)#R> [1] "Douglas" "Bayfield" "Ashland"The levels of a factor variable and their order may be seen with levels().
levels(bears$loc)#R> [1] "Douglas" "Bayfield" "Ashland"
In the previous examples, the $ notation was used to identify a particular variable (i.e., loc) within a data.frame (bears). Think of variables as being nested inside data.frames and, thus, to access the variable you must first identify the data.frame in which it exists and then the name of the variable. The $ simply separates the data.frame from the variable.
bears$length.cm#R> [1] 139.0 138.0 139.0 120.5 149.0 141.0 141.0 150.0 166.0 151.5 129.5 150.0bears$loc#R> [1] Bayfield Bayfield Bayfield Bayfield Bayfield Ashland Ashland Douglas
#R> [9] Douglas Douglas Douglas Douglas
#R> Levels: Douglas Bayfield Ashland
23.3 Vectors
Data.frames are the primary structure in which to store real data. However, much simpler situations that don’t require a data.frame may arise. In R, items of the same data type (see [Data Types]) are stored in a one-dimensional vector. Vectors are usually displayed in one row (with many columns), but they may also be thought of as a single column (with many rows). Items are entered into a vector with c(), where the individual arguments are specific numbers, characters, or logical values.79 Items for a vector of characters must be contained within paired quotes.
( v <- c(1,2,5) )#R> [1] 1 2 5( y <- c("Iowa","Minnesota","Wisconsin") )#R> [1] "Iowa" "Minnesota" "Wisconsin"Single variables from a data.frame are vectors.
bears$length.cm#R> [1] 139.0 138.0 139.0 120.5 149.0 141.0 141.0 150.0 166.0 151.5 129.5 150.0Vectors that are not extracted from a data.frame will only be used in this course for very simple lists of items, usually as arguments in a function.