Module 11 Sampling Distributions
Statistical inference is the process of making a conclusion about the parameter of a population based on the statistic computed from a sample. This process is difficult becauses statistics depend on the specific individuals in the sample and, thus, vary from sample to sample. For example, recall from Section 2.2 that the mean length of fish differed among four samples “taken” from Square Lake. Thus, to make conclusions about the population from the sample, the distribution (i.e., shape, center, and dispersion) of the statistic computed from all possible samples must be understood.49 In this module, the distribution of statistics from all possible samples is explored and generalizations are defined that can be used to make inferences. In subsequent modules, this information, along with results from a single sample, will be used to make specific inferences about the population.
Statistical inference requires considering sampling variability.
11.1 What is a Sampling Distribution?
11.1.1 Definitions and Characteristics
A Sampling distribution is the distribution of values of a particular statistic computed from all possible samples of the same size from the same population. The discussion of sampling distributions and all subsequent theories related to statistical inference are based on repeated samples from the same population. As these theories are developed, we will consider taking multiple samples; however, after the theories have been developed, then only one sample will be taken with the theory then being applied to those results. Thus, it is important to note that only one sample is ever actually taken from a population.
The concept of a sampling distribution is illustrated with a population of six students that scored 6, 6, 4, 5, 7 and 8 points, respectively, on an 8-point quiz. The mean of this population is μ= 6.000 points and the standard deviation is σ=1.414 points. Suppose that every sample of size n=2 is extracted from this population and that the sample mean is computed for each sample (Table 11.1).50
| Sample | Scores | Mean |
|---|---|---|
| 1 | 6, 6 | 6.0 |
| 2 | 6, 4 | 5.0 |
| 3 | 6, 5 | 5.5 |
| 4 | 6, 7 | 6.5 |
| 5 | 6, 8 | 7.0 |
| 6 | 6, 4 | 5.0 |
| 7 | 6, 5 | 5.5 |
| 8 | 6, 7 | 6.5 |
| 9 | 6, 8 | 7.0 |
| 10 | 4, 5 | 4.5 |
| 11 | 4, 7 | 5.5 |
| 12 | 4, 8 | 6.0 |
| 13 | 5, 7 | 6.0 |
| 14 | 5, 8 | 6.5 |
| 15 | 7, 8 | 7.5 |
Again, a sampling distribution shows the values of a statistic from all possible samples. Thus, the sampling distribution of \(\bar{\text{x}}\) from samples of n=2 from this population is the histogram of the 15 sample means in Table 11.1 (Figure 11.1).51
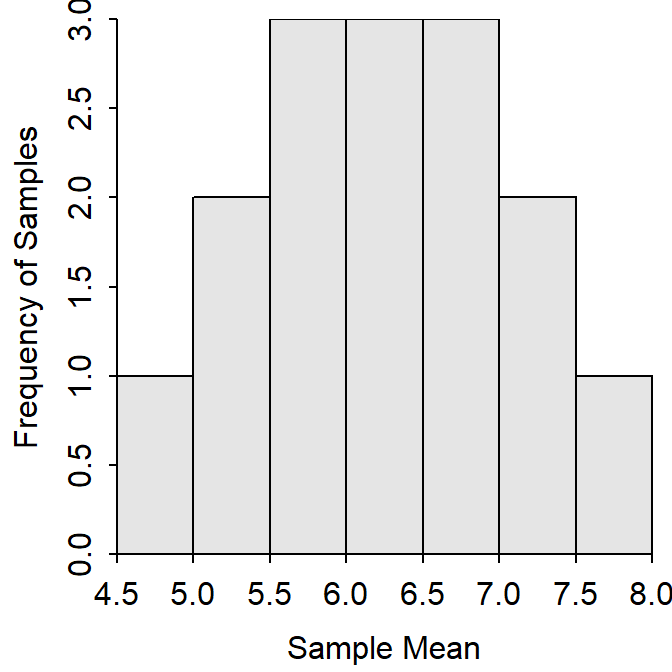
Figure 11.1: Sampling distribution of mean quiz scores from samples of n=2 from the quiz score population.
The mean (=6.000) and standard deviation (=0.845) of the 15 sample means are measures of center and dispersion for the sampling distribution. The standard deviation of statistics (i.e., dispersion of the sampling distribution) is generally referred to as the standard error of the statistic (abbreviated as SEstat). This new terminology is used to keep the dispersion of the sampling distribution separate from the dispersion of individuals in the population. Thus, the standard deviation of all possible sample means is referred to as the standard error of the sample means (SE\(_{\bar{\text{x}}}\)), which is 0.845 in this example. The standard deviation is the dispersion of individuals in the population and is 1.414 in this example.
This example illustrates three major concepts concerning sampling distributions. First, the sampling distribution will more closely resemble a normal distribution than the original population distribution (unless, of course, the original population distribution was normal).
Second, the center (i.e., mean) of the sampling distribution will equal the parameter that the statistic was intended to estimate (e.g., a sample mean is intended to be an estimate of the population mean). In this example, the mean of all possible sample means (= 6.000 points) is equal to the mean of the original population (μ=6.000 points). A statistic is said to be unbiased if the center (mean) of its sampling distribution equals the parameter it was intended to estimate. This example illustrates that the sample mean is an unbiased estimate of the population mean.
Third, the standard error of the statistic is less than the standard deviation of the original population. In other words, the dispersion of statistics is less than the dispersion of individuals in the population. For example, the dispersion of individuals in the population is σ=1.414 points, whereas the dispersion of statistics from all possible samples is SE\(_{\bar{\text{x}}}=\) 0.845 points.
All statistics in this course are unbiased, which means that each statistic will equal its corresponding parameter, on average.
11.1.2 Critical Distinction
Three distributions are considered in statistics:
- the sampling distribution is the distribution of a statistic computed from all possible samples of the same size from the same population,
- the population distribution is the distribution of all individuals in a population (see Module 6), and
- the sample distribution is the distribution of all individuals in a sample (see histograms in Module 4).
For making inferences, it will be important to distinguish between population and sampling distributions. To do so, keep in mind that the sampling distribution is about statistics, whereas the population and sample distributions are about individuals.
Just as importantly, remember that a standard error measures the dispersion among statistics (i.e., sampling variability), whereas a standard deviation measures dispersion among individuals (i.e., natural variability). Specifically, the population standard deviation (σ) is the dispersion of individuals in a population distribution, whereas the standard error is the dispersion of a statistic (e.g., sample mean) in a sampling distribution.
11.1.3 Dependencies
The sampling distribution of sample means from samples of n=2 from the population of quizzes was shown in Figure 11.1. The sampling distribution will look different if any other sample size is used. For example, the samples and means from each sample of n=3 are shown in Table 11.2.
| Sample | Scores | Mean |
|---|---|---|
| 1 | 6, 6, 4 | 5.333 |
| 2 | 6, 6, 5 | 5.667 |
| 3 | 6, 6, 7 | 6.333 |
| 4 | 6, 6, 8 | 6.667 |
| 5 | 6, 4, 5 | 5.000 |
| 6 | 6, 4, 7 | 5.667 |
| 7 | 6, 4, 8 | 6.000 |
| 8 | 6, 5, 7 | 6.000 |
| 9 | 6, 5, 8 | 6.333 |
| 10 | 6, 7, 8 | 7.000 |
| 11 | 6, 4, 5 | 5.000 |
| 12 | 6, 4, 7 | 5.667 |
| 13 | 6, 4, 8 | 6.000 |
| 14 | 6, 5, 7 | 6.000 |
| 15 | 6, 5, 8 | 6.333 |
| 16 | 6, 7, 8 | 7.000 |
| 17 | 4, 5, 7 | 5.333 |
| 18 | 4, 5, 8 | 5.667 |
| 19 | 4, 7, 8 | 6.333 |
| 20 | 5, 7, 8 | 6.667 |
The mean of these means is 6.000, the standard error is 0.592, and the sampling distribution is symmetric, perhaps approximately normal (Figure 11.2). The three major characteristics of sampling distributions noted in Section 11.1.1 are still true: the sampling distribution is still more normal than the original population, the sample mean is still unbiased (i.e, the mean of the means is equal to μ), and the standard error is smaller than the standard deviation of the original population. However, also take note that the standard error of the sample mean is smaller from samples of n=3 than from n=2.52
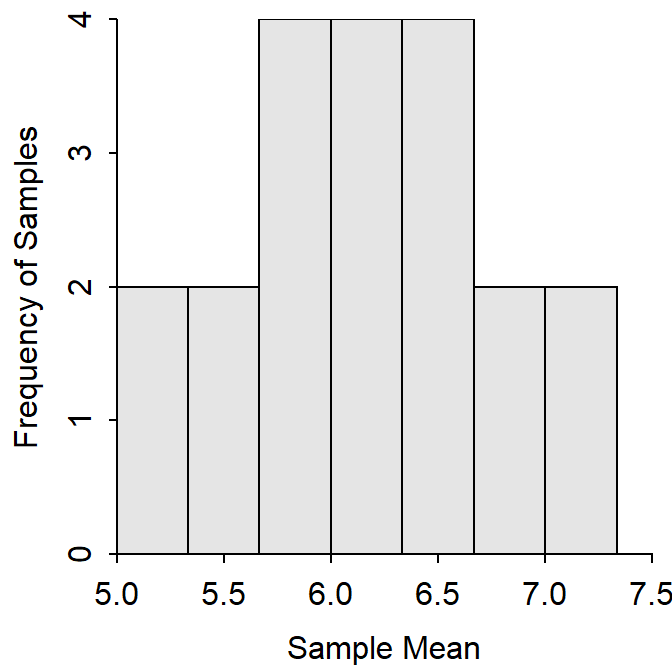
Figure 11.2: Sampling distribution of mean quiz scores from samples of n=3 from the quiz score population.
The sampling distribution will also be different if the statistic changes; e.g, if the sample median rather than sample mean is computed in each sample. Before showing the results of each sample, note that the population median (i.e., the median of the individuals in the population — 6, 6, 4, 5, 7, and 8) is 6.0 points. The sample median from each sample is shown in Table 11.3 and the actual sampling distribution is shown in Figure 11.3. Note that the sampling distribution of the sample medians is still “more” normal than the original population distribution, the mean of the sample medians (=6.000 points; thus, the sample median is also unbiased), and this sampling distribution differs from the sampling distribution of sample means (Figure 11.2).
| Sample | Scores | Mean |
|---|---|---|
| 1 | 6, 6, 4 | 6 |
| 2 | 6, 6, 5 | 6 |
| 3 | 6, 6, 7 | 6 |
| 4 | 6, 6, 8 | 6 |
| 5 | 6, 4, 5 | 5 |
| 6 | 6, 4, 7 | 6 |
| 7 | 6, 4, 8 | 6 |
| 8 | 6, 5, 7 | 6 |
| 9 | 6, 5, 8 | 6 |
| 10 | 6, 7, 8 | 7 |
| 11 | 6, 4, 5 | 5 |
| 12 | 6, 4, 7 | 6 |
| 13 | 6, 4, 8 | 6 |
| 14 | 6, 5, 7 | 6 |
| 15 | 6, 5, 8 | 6 |
| 16 | 6, 7, 8 | 7 |
| 17 | 4, 5, 7 | 5 |
| 18 | 4, 5, 8 | 5 |
| 19 | 4, 7, 8 | 7 |
| 20 | 5, 7, 8 | 7 |
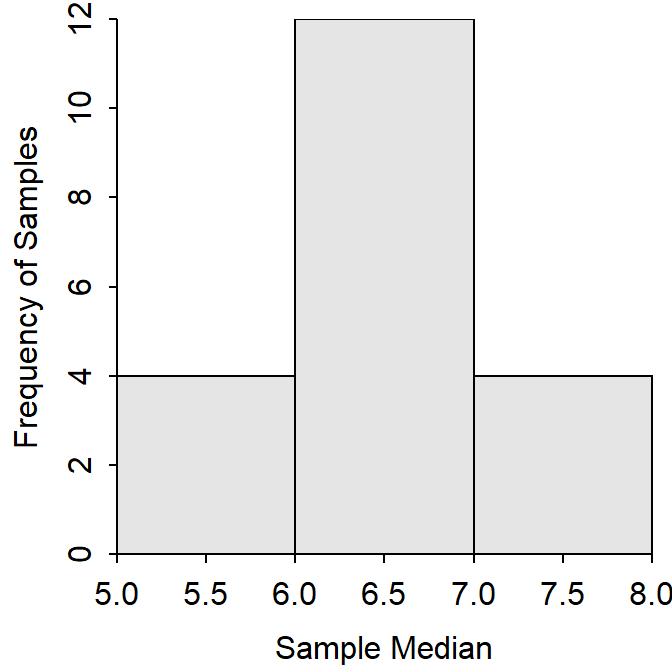
Figure 11.3: Sampling distribution of median quiz scores from n=3 samples from the quiz score population.
These examples demonstrate that the naming of a sampling distribution must be specific. For example, the first sampling distribution in this module should be described as the “sampling distribution of sample means from samples of n=2.” This last example should be described as the “sampling distribution of sample medians from samples of n=3.” Doing this with each distribution reinforces the point that sampling distributions depend on the sample size and the statistic calculated.
Each sampling distribution should be specifically labeled with the statistic calculated and the sample size of the samples, because the specific characteristics of a sampling distribution depend on the statistic calculated and the sample size.
11.1.4 Simulating a Sampling Distribution
Exact sampling distributions can only be computed for very small samples taken from a small population. Exact sampling distributions are difficult to show for even moderate sample sizes from moderately-sized populations. For example, there are 15504 unique samples of n=5 from a population of 20 individuals.
There are two ways to examine sampling distributions in situations with large sample and population sizes. First, theorems exist that describe the specifics of sampling distributions under certain conditions. One such theorem is described in Section 11.2. Second, the computer can take many (hundreds or thousands) samples and compute the statistic for each. These statistics can then be summarized to give an indication of what the actual sampling distribution would look like. This process is called “simulating a sampling distribution.” We will simulate some sampling distributions here so that the theorem in Section 11.2 will be easier to understand.
Sampling distributions are simulated by drawing many samples from a population, computing the statistic of interest for each sample, and constructing a histogram of those statistics (Figure 11.4). The computer is helpful with this simulation; however, keep in mind that the computer is basically following the same process as used in Section 11.1.1, with the exception that not every sample is taken.
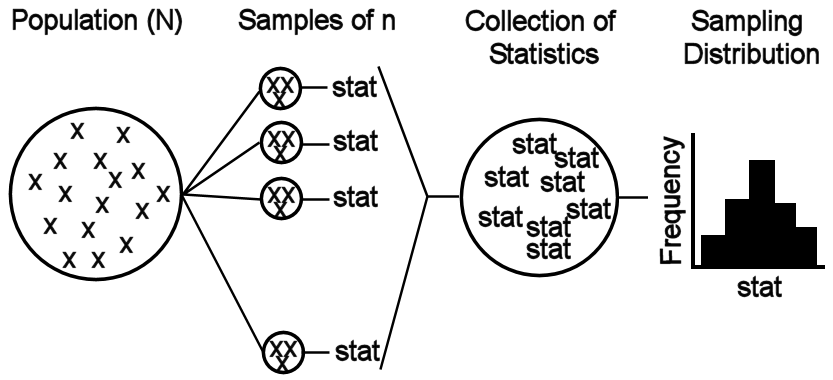
Figure 11.4: Schematic representation of the process for simulating a sampling distribution.
Let’s return to the Square Lake fish population from Section 2.2 to illustrate simulating a sampling distribution. Recall that this is a hypothetical population with 1015 fish, a population distribution shown in Figure 2.1, and parameters shown in Table 2.1. Further recall that four samples of n=50 were removed from this population and summarized in Tables 2.2 and 2.3. Suppose, that an additional 996 samples of n=50 were extracted in exactly the same way as the first four, the sample mean was computed in each sample, and the 1000 sample means were collected to form the histogram in Figure 11.5. This histogram is a simulated sampling distribution of sample means because it represents the distribution of sample means from 1000, rather than all possible, samples.
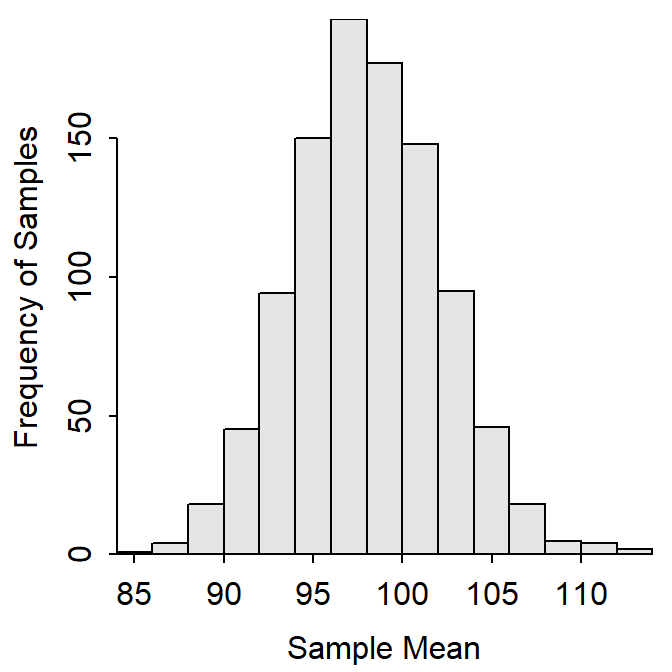
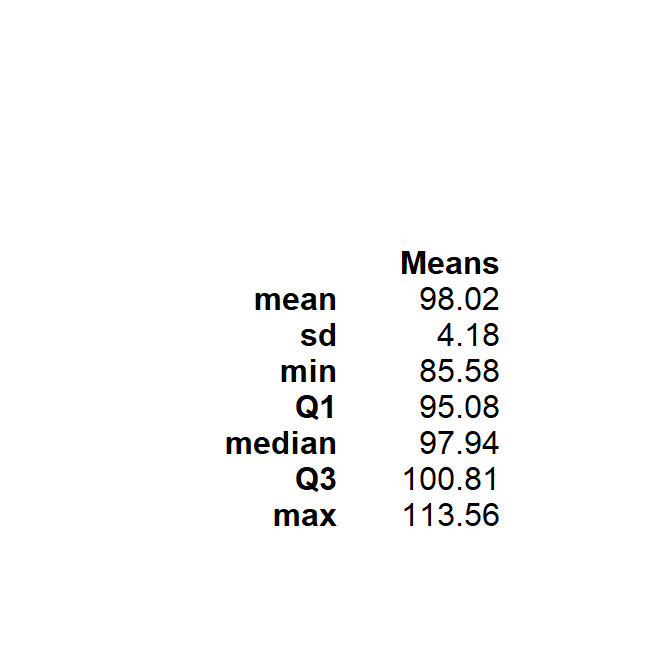
Figure 11.5: Histogram (Left) and summary statistics (Right) from 1000 sample mean total lengths computed from samples of n=50 from the Square Lake fish population.
As with the actual sampling distributions discussed previously, three characteristics (shape, center, and dispersion) are examined with simulated sampling distributions. First, Figure 11.5 looks at least approximately normally distributed. Second, the mean of the 1000 means (=98.02) is approximately equal to the mean of the original 1015 fish in Square Lake (=98.06). These two values are not exactly the same because the simulated sampling distribution was constructed from only a “few” rather than all possible samples. Third, the standard error of the sample means (=4.18) is much less than the standard deviation of individuals in the original population (=31.49). So, within reasonable approximation, the concepts identified with actual sampling distributions also appear to hold for simulated sampling distributions.
As before, computing a different statistic on each sample results in a different sampling distribution. This is illustrated by comparing the sampling distributions of a variety of statistics from the same 1000 samples of size n=50 taken above (Figure 11.6).
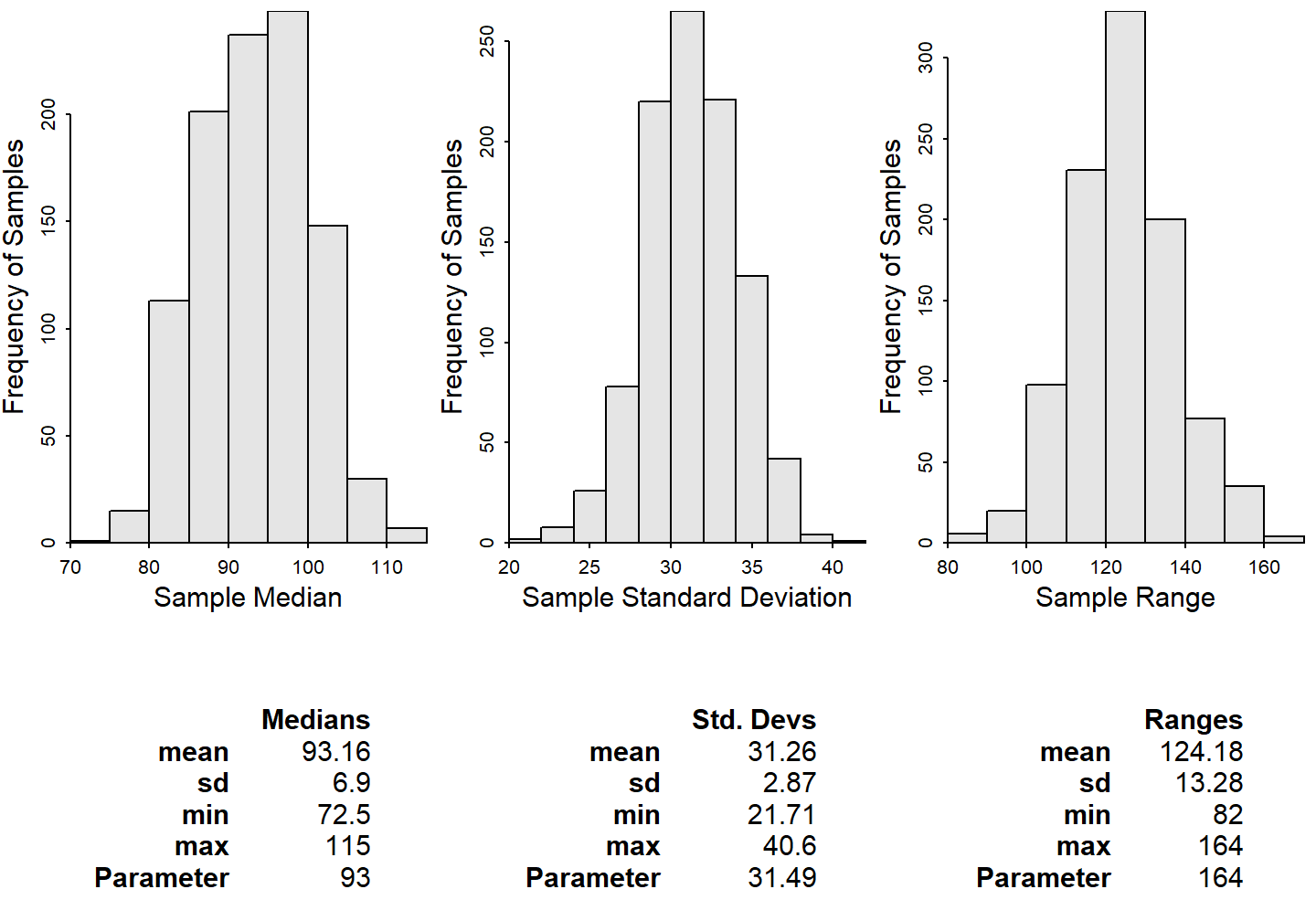
Figure 11.6: Histograms from 1000 sample median (Left), standard deviation (Center), and range (Right) of total lengths computed from samples of n=50 from the Square Lake fish population. Note that the value in the parameter row is the value computed from the entire population.
Simulating a sampling distribution by taking many samples of the same size from a population is powerful for two reasons. First, it reinforces the ideas of sampling variability – i.e., each sample results in a slightly different statistic. Second, the entire concept of inferential statistics is based on theoretical sampling distributions. Simulating sampling distributions will allow us to check this theory and better visualize the theoretical concepts. From this module forward, though, remember that sampling distributions are simulated primarily as a check of theoretical concepts. In real-life, only one sample is taken from the population and the theory is used to identify the specifics of the sampling distribution.
Simulating sampling distributions is a tool for checking the theory concerning sampling distributions; however, in “real-life” only one sample from the population is needed.
11.2 Central Limit Theorem
The sampling distribution of the sample mean was examined in the previous sections by taking all possible samples from a small population (Section 11.1.1) or taking a large number of samples from a large population (Section 11.1.4). In both instances, it was observed that the sampling distribution of the sample mean was approximately normally distributed, centered on the true mean of the population, and had a standard error that was smaller than the standard deviation of the population and decreased as n increased. In this section, the Central Limit Theorem (CLT) is introduced and explored as a method to identify the specific characteristics of the sampling distribution of the sample mean without going through the process of extracting all or multiple samples from the population.
The CLT specifically addresses the shape, center, and dispersion of the sampling distribution of the sample means by stating that \(\bar{\text{x}}\)~N(μ,\(\frac{\sigma}{\sqrt{n}}\)) as long as
- n≥30,
- n≥15 and the population distribution is not strongly skewed, or
- the population distribution is normally distributed.
Thus, the sampling distribution of \(\bar{\text{x}}\) should be normally distributed no matter what the shape of the population distribution is as long as n≥30. The CLT also suggests that \(\bar{\text{x}}\) is unbiased and that the formula for the SE\(_{\bar{\text{x}}}\) is \(\frac{\sigma}{\sqrt{\text{n}}}\) regardless of the size of n. In other words, n impacts the dispersion of the sampling distribution of the sample means, but not the center or formula for computing the standard error.
The validity of the CLT can be examined by simulating several (with different n) sampling distributions of \(\bar{\text{x}}\) from the Square Lake population and from a strongly right-skewed distribution (Figure 11.7). In Figure 11.7 note that the two population distributions are shown at the very top of the figure, samplng distributions use n=5, 15, 30, and 60 are shown below that, and that expected means and SEs based on the CLT are shown on the left side of each subplot and observed means and SEs computed from the results are shown on the right side of each subplot. Please spend a few minutes to examine the following characteristics of these plots.
- How do the shapes of the sampling distributions change with increasing n?
- How well do the observed means compare to the expected means? Does this change with increasing n?
- How well do the observed SEs compare to the expected SEs? Does this change with increasing n?
- How do the SEs change with increasing n?
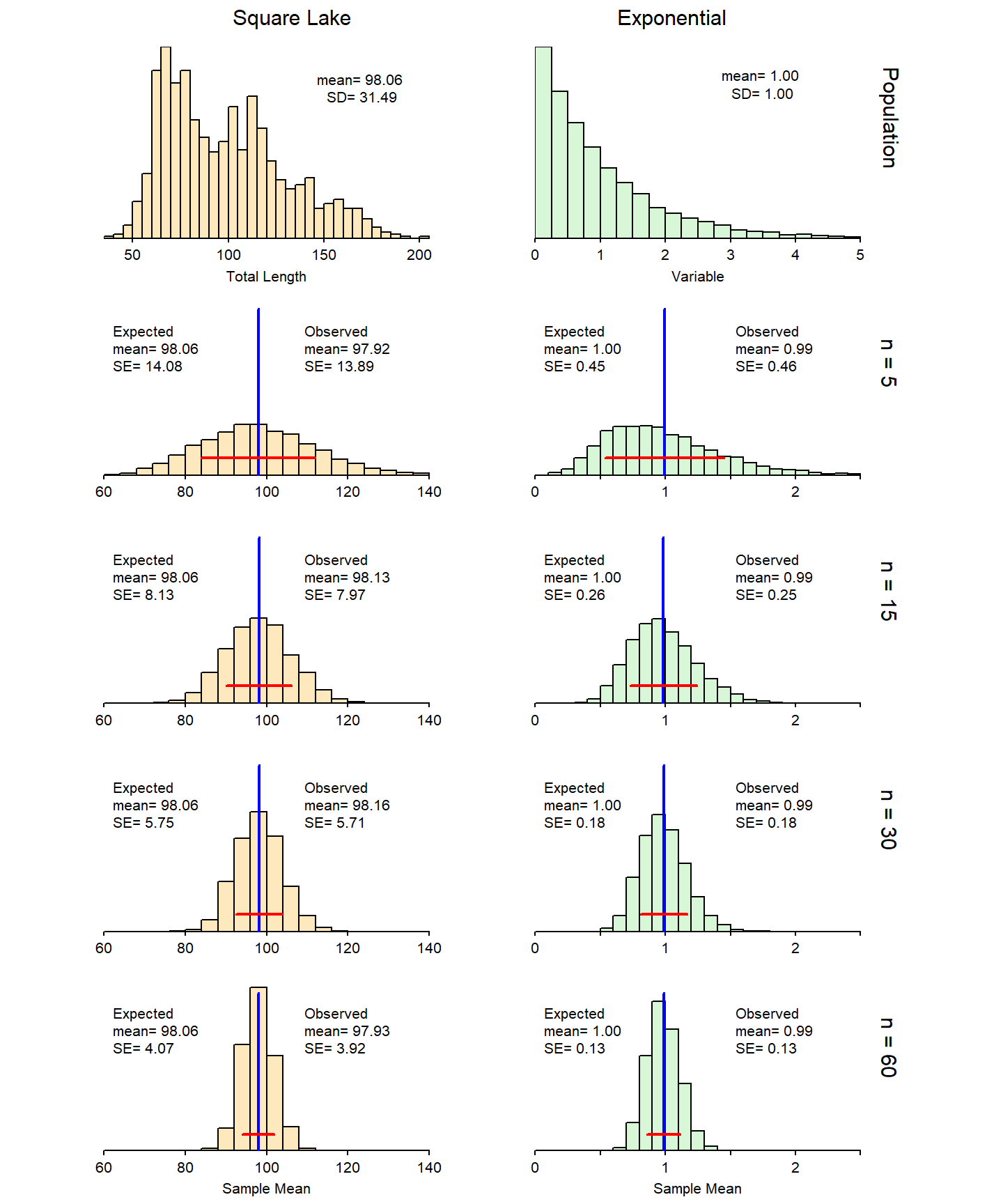
Figure 11.7: Sampling distribution of the sample mean simulated from 5000 samples of four different sample sizes extracted from the Square Lake fish population (Left) and a strongly right-skewed population (Right). The shapes of the populations are shown in the top histogram. On each simulated sampling distribution, the vertical blue line is the mean of the 5000 means and the horizontal red line represents ±1SE from the mean.
Several observations about the CLT can be made from Figure 11.7. First, the sampling distribution is approximately normal for n≥30 for both scenarios and is approximately normal for smaller n for the Square Lake example because that population is only slightly skewed. Second, the means of all sampling distributions in both examples are approximately equal to μ, regardless of n. Third, the dispersion of the sampling distributions (i.e., the SE of the means) becomes smaller with increasing n and the SE from the simulated results closely match the expected SEs. In fact, it appears that all expectations from the CLT about shape, center, and dispersion are upheld. Thus, it appears that the CLT can accurately predict what the sampling distribution of \(\bar{\text{x}}\) is so that we don’t have to take all or multiple samples from the population.
11.3 Accuracy and Precision
Accuracy and precision are often used to describe characteristics of a sampling distribution. Accuracy refers to how closely a statistic estimates the intended parameter. If, on average, a statistic is approximately equal to the parameter it was intended to estimate, then the statistic is considered accurate. Unbiased statistics are also accurate statistics. Precision refers to the repeatability of a statistic. A statistic is considered to be precise if multiple samples produce similar statistics. The standard error is a measure of precision; i.e., a high SE means low precision and a low SE means high precision.
The targets in Figure 11.8 provide an intuitive interpretation of accuracy and precision, whereas the sampling distributions (i.e., histograms) are what statisticians look at to identify accuracy and precision. Targets in which the blue plus (i.e., mean of the means) is close to the bullseye are considered accurate (i.e., unbiased). Similarly, sampling distributions where the observed center (i.e., blue vertical line) is very close to the actual parameter (i.e., black tick labeled with a “T”) are considered accurate. Targets in which the red dots are closely clustered are considered precise. Similarly, sampling distributions that exhibit little variability (low dispersion) are considered precise.
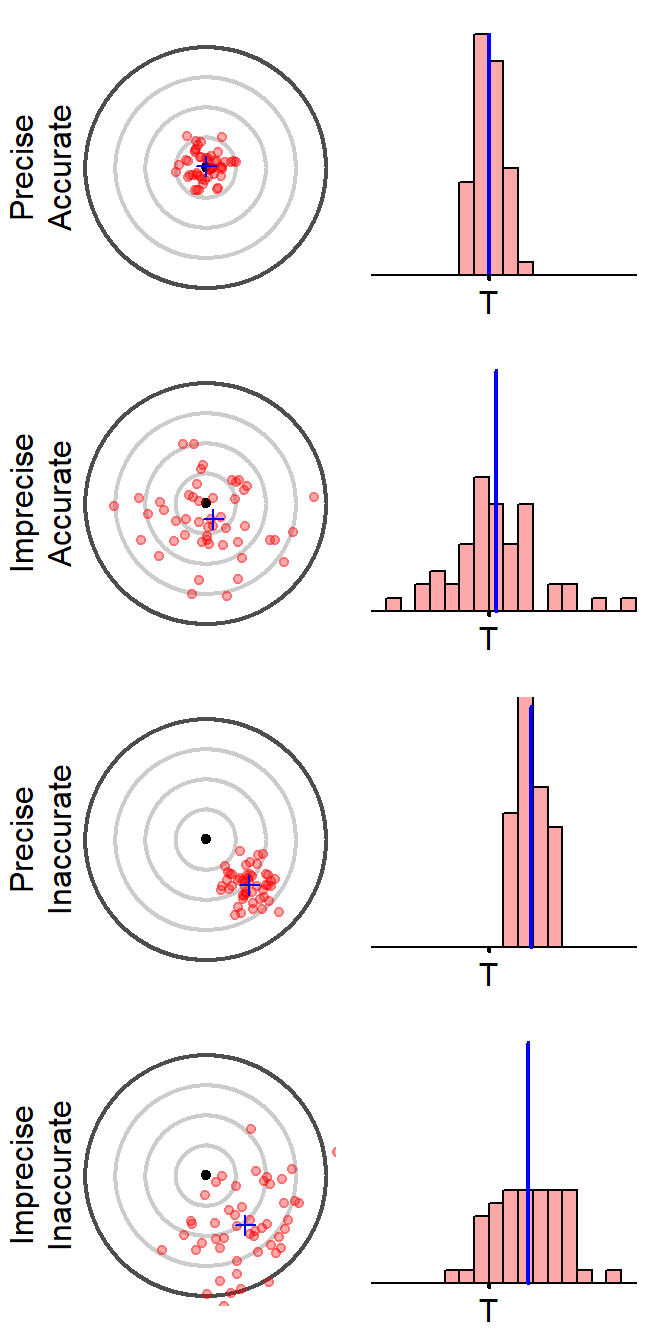
Figure 11.8: The center of each target (i.e., the bullseye) and the point marked with a “T” (for “truth”) represent the parameter of interest. Each dot on the target represents a statistic computed from a single sample and, thus, the many red dots on each target represent repeated samplings from the same population. The center of the samples (analogous to the center of the sampling distribution) is denoted by a blue plus-sign on the target and a blue vertical line on the histogram.
As a more concrete example, supposed that a researcher takes five samples from a population with μ=100. You know that the sample means (\(\bar{\text{x}}\)) computed from these five samples will not be exactly equal because of sampling variability. However, the means will be considered accurate if their average is equal to μ=100. In addition, the means will be considered precise if they are relatively close together (i.e., little sampling variability is exhibited). With this in mind, consider the four situations below where the values represent the five sample means.
- 98, 99, 100, 101, 102
- These are accurate because they average to μ=100 and precise because they vary very little (SE=0.71).
- 80, 90, 100, 105, 125
- These are accurate because they average to μ=100 and imprecise because they vary quite a bit (SE=7.6).
- 60, 61, 62, 63, 64
- These are inaccurate because they do not average to μ=100 (=62) and precise because they vary very little (SE=0.71).
- 30, 50, 70, 100, 120
- These are inaccurate because they do not average to μ=100 (=74) and imprecise because they vary quite a bit (SE=16.3).
The precision of a statistics is measured by the standard error (SE); relatively small values of the SE mean the statistic is precise.
These samples are found by putting the values into a vector with
vals <- c(6,6,4,5,7,8)and then usingcombn(vals,2). The means are found withmns <- as.numeric(combn(vals,2,mean)).↩︎The histogram is constructed with
hist(~mns,w=0.5).↩︎One should also look at the results from n=4 in one of the online Review Exercises.↩︎